平台资源
代码优化
优化案例一:破世界纪录!π 2.0 完成粒子数目最多的 N 体模拟
上海交通大学网络信息中心联合上海交通大学天文系、厦门大学天文系等单位,使用 π 2.0 集群 512 节点 20480 核心完成了宇宙大尺度结构N体模拟 Cosmo-π 测试。Cosmo-π 包含约 4.4 万亿个粒子,并追踪了 137 亿年以来的宇宙演化,打破了之前 TianNu 数值模拟(在天河二号上,使用 13824 节点 331,776 核心完成,3 万亿粒子)的世界记录,是目前世界上粒子数目最多的天文学 N 体模拟。

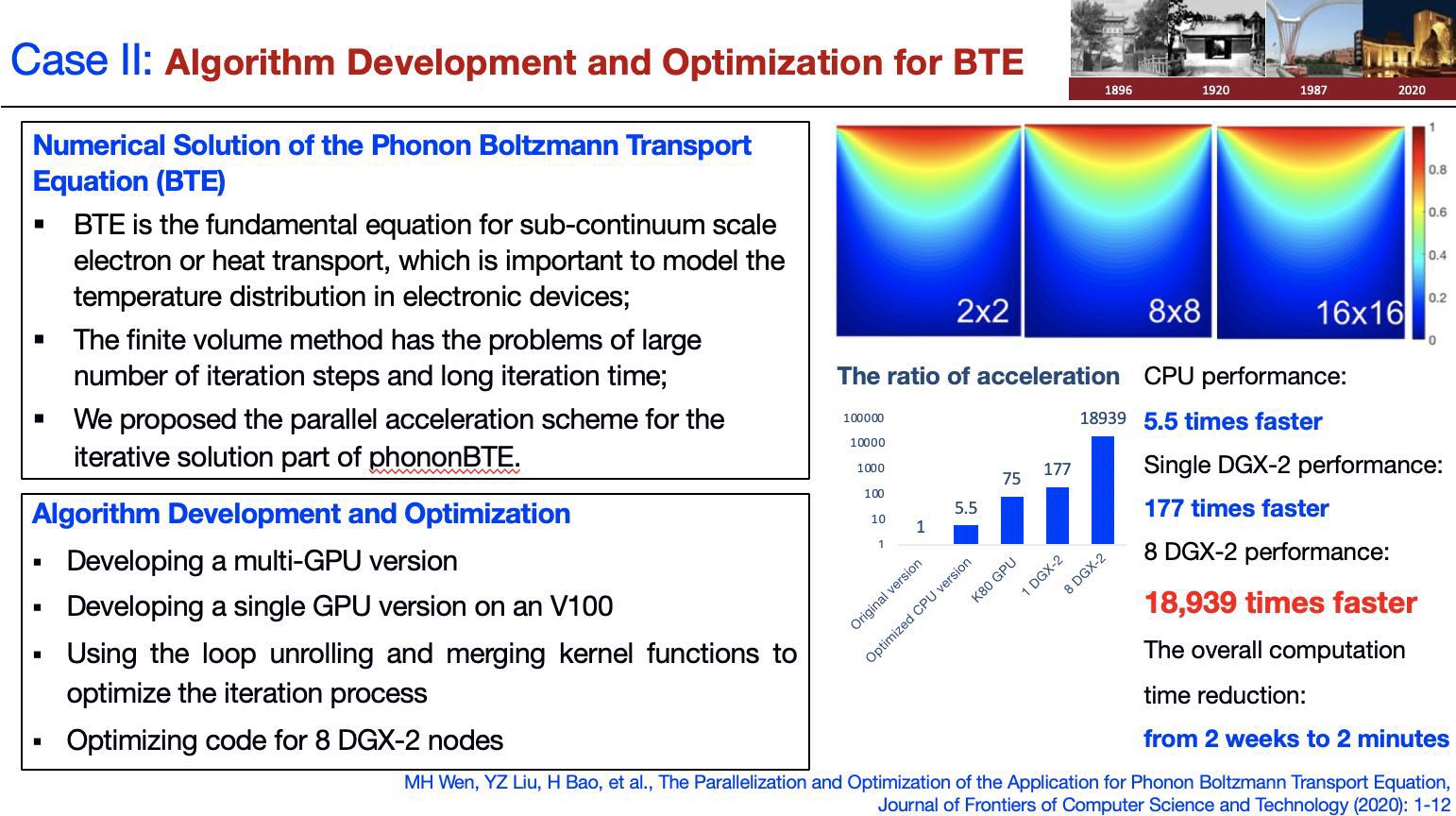
优化案例二:声子BTE应用的并行和优化研究
声子玻尔兹曼输运方程(BTE)可以有效地模拟介观尺度下的导热问题,相比于随机性方法,以有限体积法为代表的确定性方法求解声子BTE方程被认为更有希望解决工程实际问题。但是有限体积法求解BTE具有迭代步数多,迭代时间长的问题。为此本文将声子BTE方程迭代求解部分移植到GPU上,并设计适当的线程分配方式及数据存储格式,采用循环展开和内核融合等优化手段对迭代过程进行并行加速。此外,本文采用基于角方向的并行策略,使用MPI+CUDA, CUDA-Aware MPI 和NCCL(NVIDIA Collective Communications Library)函数的方式实现了声子BTE求解多GPU并行版本。实验结果表明,相较于Intel Xeon Gold 6248上的串行版本,我们在单块V100 GPU上获得了最大31.5倍的加速。同时使用NCCL函数的GPU并行版本在8台DGX-2节点共计128块V100 GPU上最高达到了83%的并行效率,比MPI+CUDA版本提升57%。